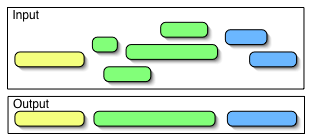
The goal is to return the minimal set of regions in a string that cover all occurrences of terms.
Most languages have a mechanism for finding one string in another. A situation that I've been faced with many times involves the highlighting of text strings in a larger body of text. Specifically, highlighting multiple text strings that may overlap in the resulting highlighting process.
The text markup syntax du jour is HTML. Some HTML rendering software might choose to interpret up code like <X>this <X>is</X> marked</X> in a way such that the word marked is not marked up by the tag X. Most browsers these days work nicely with tags like b, but imagine a tag like span with properties that draw a thin border around the marked text. In such a situation, a border will be drawn twice, which is undesirable.
The more interesting challenge that this situation evokes is that of finding non-overlapping regions from a set of arbitrarily placed and often overlapping regions of arbitrary length. In other words, given a set of tuples that define (start,end) positions, return the smallest set of tuples whose (start,end) positions cover all the regions in the input. Here is a picture to illustrate what I mean:
There is a pretty naiive way of solving this problem. You start off with an empty set of regions, and iterate over all the regions that have to be covered. As you encounter each region, you inspect your new set of regions, and decide if it ought to be augmented (by replacing some regions with a single longer one) or extended. Here is a function that does it:
# given a list of tuples that define (start,end) indices, return
# a list of (sometimes new) tuples that cover all (start,end) segments
def overlap (segments):
segments.sort()
new_segments = []
for startpos, endpos in segments:
#print "Considering segment (%s,%s)" % (startpos, endpos)
# find segment numbers where this segment overlaps with the new segments
overlap_start_segment = -1
overlap_end_segment = -1
# for each new segment
for i in range(len(new_segments)):
seg_startpos = new_segments[i][0]
seg_endpos = new_segments[i][1]
#print " Inspecting new segment (%s,%s)" % (seg_startpos, seg_endpos)
if seg_startpos-1 <= startpos <= seg_endpos: # the segment begins in this new_segment
overlap_start_segment = i
if seg_startpos-1 <= endpos <= seg_endpos: # the segment ends in this new_segment
overlap_end_segment = i
# special case 1
if overlap_start_segment == -1 and overlap_end_segment == -1: # brand new segment
new_segment = (startpos, endpos)
#print "Adding brand new segment (%s,%s)" % (startpos, endpos)
new_segments.insert(0, new_segment)
# special case 2
elif overlap_start_segment == -1 and overlap_end_segment != -1: # partially overlaps one or more segments from the left
new_segment = (startpos, new_segments[overlap_end_segment][1])
#print "Adding new segment (%s,%s) to replace segments %s thru %s" % (startpos, new_segments[overlap_end_segment][1], 0, overlap_end_segment)
for i in range(0,overlap_end_segment):
new_segments.pop(0)
new_segments.insert(0, new_segment)
# special case 3
elif overlap_start_segment != -1 and overlap_end_segment == -1: # partially overlaps one or more segments from the right
new_segment = (new_segments[overlap_end_segment][0], endpos)
#print "Adding new segment (%s,%s) to replace segments %s thru %s" % (startpos, new_segments[overlap_end_segment][1], overlap_start_segment, len(new_segments))
for i in range(overlap_start_segment, len(new_segments)):
new_segments.pop(overlap_start_segment)
new_segments.insert(0, new_segment)
else:
# measure how far apart the two overlapping segments are
segment_distance = overlap_end_segment - overlap_start_segment
if segment_distance == 0: #start and end in the same new segment
#print "No need to add this segment"
pass # do nothing, no need to add this
else:
#print "Adding this segment to replace segments %s thru %s" % (overlap_start_segment, overlap_end_segment)
new_segment = (new_segments[overlap_start_segment][0], new_segments[overlap_end_segment][1])
for i in range(segment_distance):
new_segments.pop(overlap_start_segment)
new_segments.insert(0, new_segment)
new_segments.sort()
#print "New segments are:"
#for i in range(len(new_segments)):
# print i, new_segments[i]
return new_segments
The less interesting task in this long endeavor is that of finding overlapping strings in a string. Surprisingly, there is no built-in facility to do this in Python. So, I do it manually with this snippet:
# return list of (start,end) tuples for all places in string that contain
# a term in terms
def find_matches (string, terms):
matches = []
for t in terms:
#print "Looking for term >%s<" % t
substring = string
substring_index = 0
done = False
while not done and len(substring)>0:
matched = sre.search(t, substring)
if matched:
startpos, endpos = matched.span()
#print " Found term in >%s< at location %s-%s" % (substring, startpos, endpos)
matches.append((substring_index + startpos, substring_index + endpos))
substring = substring[endpos:]
substring_index += endpos
else:
#print " Could not find term in >%s<, finishing" % substring
done = True
matches.sort()
return matches
Putting this all together, we can produce output like this:
Text: This sentence contains many repeated substrings Terms: "sent" "sentence" "many" "substr" "string" Matches: (5, 9) "sent" (5, 13) "sentence" (23, 27) "many" (37, 43) "substr" (40, 46) "string" Optimized matches: (5, 13) "sentence" (23, 27) "many" (37, 46) "substring"
You can download the final piece of code to produce the above output and play with it yourself. Uncommenting the print statements will produce verbose output describing the process step by step.
https://michal.guerquin.com/overlap.html, updated 2005-06-19 22:41 EDT